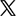An open source AI image generator is a tool that uses artificial intelligence to generate images based on the text descriptions provided by the user. It utilizes Natural Language Processing (NLP) to understand the context of the text and then uses Generative Adversarial Networks (GANs), Diffusion, Transformer, or other technologies to create new synthetic images that match the text description.
Being open source means the code, models, and training frameworks are publicly available under licenses that allow people to freely use, change, improve, and redistribute them. This enables collaboration and innovation. Meanwhile, thoughtful governance of these powerful technologies is crucial as they continue rapidly evolving.
No matter whether you are a pro seeking open source code or common users wanting to try AI image generators for free, here's a full list of recent open-source AI image models and algorithms that you can use to create images without any restriction on credits, resolutions, or speed. Additionally, there are tips for enhancing images quality with AI for printing, display, or further editing at the end of the post.

Open Source License
Notice that not all open source licenses are the same. Some, like the MIT License and the Apache License, are very permissive and allow for almost any kind of use, including commercial use and the creation of proprietary software based on the open source code. Others, like the GNU General Public License, require that any derivative works also be released under the same open-source license.
1. PixArt-Alpha
AI art models: PIXART-α
License: GNU Affero General Public License v3.0
Repository: https://github.com/PixArt-alpha/PixArt-alpha
Online demo: https://huggingface.co/spaces/PixArt-alpha/PixArt-alpha
PixArt-Alpha is a Transformer-based T2I diffusion model. Its high-quality image generation is comparable to state-of-the-art generators like Imagen, SDXL, and Midjourney. It can produce high-resolution images up to 1024px with minimal training cost, approaching commercial application standards. Through its exceptional adherence to prompts, T5 Text Encoder, and use of LLaVA captioning, it increasingly attracts creators, designers, and AI fans of all levels.
Unique Features of PixArt-Alpha
- Transformer-Based Architecture: Unlike many other models that use UNet architectures, PixArt-Alpha employs a Transformer backbone for denoising. This architecture, similar to DiT, enhances its ability to process complex text prompts effectively.
- Efficient Training: PixArt-Alpha is designed for fast training, requiring only about 10.8% to 12% of the training time needed by Stable Diffusion v1.5. This efficiency results in significant cost savings and reduced environmental impact.
- High-Resolution Image Generation: It can generate high-resolution images up to 1024px, which is a notable feature compared to many other models that often struggle with such resolutions.
- T5 Text Encoder: PixArt-Alpha uses a powerful T5 Text Encoder, which allows it to accurately follow complex text prompts. This feature is crucial for generating images that closely match the user's intent.
- Versatility and Customization: The model is versatile and allows users to prepare their own datasets, making it adaptable to specific needs and projects.
- Performance: PixArt-Alpha's image generation quality is comparable to state-of-the-art models like Imagen, SDXL, and Midjourney, despite requiring less training data and time.

2. StableStudio
AI art models: SDXL and other Stable Diffusion models
License: MIT License
Repository: https://github.com/Stability-AI/StableStudio
Online demo: None
StableStudio is an open source AI image generation tool that was recently released by Stability AI as the open source community-driven successor to DreamStudio. It allows users to generate AI images through text prompts using Stable Diffusion models for free, and contribute fixes, new features, and models. Unlike DreamStudio which was cloud-based, StableStudio is designed to be installed and run locally for more control and customization. Pre-built binaries are available. Moreover, it removes billing and API key management features.
Unique Features of StableStudio
- Community-Driven Development: StableStudio emphasizes open-source and community-driven development, allowing users to contribute to its growth and innovation. This collaborative approach fosters a dynamic ecosystem where users can extend and customize the platform.
- SDXL Model Utilization: StableStudio uses the advanced SDXL model for high-quality image generation, providing superior output quality compared to many other models.
- Web-Based Interface: It offers a user-friendly web interface that eliminates the need for additional software installations, making it accessible to a broader audience.
- Model Selection and Customization: Users can choose from a range of AI models for image generation and customize their experience through a plugin system, which supports local development and feature expansion.
- Future Chat Interface: Plans are underway to integrate a chat interface, enhancing user interaction and exploring multi-modal experiences with generative AI.
- Local Inference Support: StableStudio supports local inference through WebGPU and stable-diffusion-webui, allowing users to run the application locally and maintain control over their data.

3. InvokeAI
AI art models: Stable Diffusion models
License: Apache License
Repository: https://github.com/invoke-ai/InvokeAI
Online demo: None
InvokeAI is at the forefront of creative engines for Stable Diffusion models, providing professionals, artists, and enthusiasts with the ability to produce and design visual media using cutting-edge AI-driven technologies. It comes with a user-friendly interface and various features such as image-to-image translation, out-painting, and in-painting. It is easy to set up and runs on Windows, Mac, and Linux systems with GPU cards as low as 4 GB of RAM. Developed by an open-source network of developers, it is available on GitHub. Also, you can buy the commercial version from InvokeAI official website which offers more advanced and customizable models.
Unique Features of InvokeAI
- Unified Canvas: This feature allows users to build intricate scenes by combining and modifying multiple images. It integrates img2img, inpainting, and outpainting functionalities into a single interface, making it easier to create complex compositions.
- Prompt Engineering: InvokeAI emphasizes the importance of crafting specific prompts to guide the AI in generating images that align with the user's creative vision. This feature is crucial for achieving desired outputs.
- Custom Models: InvokeAI supports various custom models, including LoRA, LyCORIS, and LCM-LoRA, which enable users to incorporate custom subjects and styles into their creations. This flexibility allows for a personalized touch in image generation.
- ControlNet: This feature provides users with fine control over image outputs, allowing for precise adjustments in generated images.
- Image-to-Image Generation: Users can generate new images based on existing ones, enabling innovative transformations and variations.
- Enterprise-Level Security: InvokeAI offers enterprise-grade security and compliance, making it suitable for professional studios that need to protect their intellectual property.
- Cross-Platform Compatibility: InvokeAI runs on Windows, Linux, and Mac (M1 & M2), and it also has a mobile version that supports both Android and iOS devices.

4. DALL-E mini
AI art models: DALL-E mini
License: Apache License 2.0
Repository: https://github.com/borisdayma/dalle-mini
Online demo: https://huggingface.co/spaces/dalle-mini/dalle-mini
DALL-E mini is an open source version of OpenAI's DALL-E to transform texts into photos or illustrations. You have the option to host pre-trained models for text-to-image generation on your own servers, allowing you to use them for personal or commercial purposes. The patterns, clothing, and objects look reasonably in low resolution. However, the model struggles with faces and heads. The designers of DALL-E Mini also offer a paid online service called Craiyon, which utilizes a more advanced and larger version of DALL-E Mini known as DALL-E Mega, and plans to further train this model to deal with faces better.
Unique Features of DALL-E mini
- Accessibility: DALL-E Mini is designed to be more accessible than the original DALL-E model, requiring less computational power and resources. This makes it suitable for users with limited hardware capabilities.
- Transformer-Based Architecture: It uses a combination of VQGAN and BART encoders to generate images from text prompts. This architecture allows for efficient image creation, though the output quality may vary.
- Community Engagement: DALL-E Mini has become popular on social media for its quirky and sometimes disturbing outputs, encouraging users to experiment with creative and humorous prompts.
- Training Data: The model was trained on unfiltered internet data, which contributes to its ability to generate a wide range of images but also introduces biases and limitations.
- Output Style: While it can produce high-quality images, DALL-E Mini often struggles with realistic depictions of faces and people, leading to cartoonish or abstract representations.

5. DeepFloyd IF
AI art models: Multiple neural modules, base and super-resolution models, etc.
License: DeepFloyd IF License Agreement
Repository: https://github.com/deep-floyd/IF
Online demo: None
DeepFloyd IF is a powerful text-to-image cascaded pixel diffusion model developed by the Stability AI multimodal AI research lab in April 2023. It was initially seen as an open source version of Google Imagen, available on a non-commercial, research-permissible license for research labs to experiment with advanced text-to-image generation approaches. IF uses multiple neural modules to generate low-resolution samples and then upscale them to 1024px x 1024px in a cascading manner.
Unique Features of DeepFloyd IF
- Modular Architecture: DeepFloyd IF is composed of a frozen text encoder and three cascaded pixel diffusion modules. The base model generates 64x64 px images, followed by two super-resolution models that upscale to 256x256 px and 1024x1024 px, respectively.
- T5-XXL-1.1 Text Encoder: It uses a powerful T5-XXL-1.1 language model as the text encoder, which enhances its ability to understand complex text prompts and align them with generated images.
- Cross-Attention Layers: The model incorporates cross-attention layers to improve the alignment between text prompts and generated images, allowing for more accurate spatial relationships between objects.
- Photorealism: DeepFloyd IF achieves a high degree of photorealism, reflected in its impressive zero-shot FID score of 6.66 on the COCO dataset.
- Aspect Ratio Flexibility: It can generate images with non-standard aspect ratios, including vertical or horizontal orientations, in addition to standard square aspects.

6. Openjourney
AI art models: Openjourney, Openjourney v4
License: MIT License
Repository: https://huggingface.co/prompthero/openjourney/tree/main
Online demo: https://prompthero.com/users/sign_in (Sign in and select Openjourney model)
Openjourney is a fine-tuned text-to-image model created by PromptHero based on Stable Diffusion. The developers said they have trained this model with over 124,000 images created by Midjourney v4. So it can create artwork that resembles the style of Midjourney for free. In Openjourney, users are free to set the final resolution ranging from 128px to 1024px. In addition to online interactive demos, you can download the model checkpoint file and set up a UI for running Stable Diffusion models like AUTOMATIC1111. To get the best outcome, you can experiment with various text prompts and models in it.
Unique Features of Openjourney
- Midjourney-Style Outputs: OpenJourney is specifically fine-tuned to generate images in the style of Midjourney, a popular AI model known for its detailed and imaginative artwork. This includes fantastical landscapes, realistic portraits, and scenes with a distinct visual style.
- Stable Diffusion Base: OpenJourney is built on top of Stable Diffusion v1.5, which provides a robust foundation for text-to-image synthesis. This allows OpenJourney to leverage the strengths of Stable Diffusion while offering a unique aesthetic.
- Customization and Control: Users can control various parameters such as image size, number of outputs, guidance scale, and seed value to achieve deterministic outputs. This level of control is beneficial for artists and designers seeking specific styles or effects.
- Artistic Applications: OpenJourney is particularly useful for conceptual art, game asset creation, and illustration. It can quickly generate ideas or concepts for creative projects, making it a valuable tool for designers and artists.

7. Waifu Diffusion
AI art models: waifu-diffusion (based on Stable Diffusion)
License: CreativeML OpenRAIL License
Repository: https://github.com/harubaru/waifu-diffusion/
Online demo: None
Waifu Diffusion is a powerful text-to-image model that creates impressive anime images based on text descriptions. It has had a significant impact on the anime community and is highly regarded as one of the best AI art tools in the industry. It leverages AI technology to produce a diverse range of images capturing specific traits, scenes, and emotions. The model can also learn from user feedback and fine-tune its generation processes, resulting in more accurate and impressive images. Artists, anime enthusiasts, researchers, or anyone interested in AIGC can explore endless possibilities in this tool.
Unique Features of Waifu Diffusion
- Anime-Style Outputs: Waifu Diffusion is fine-tuned on high-quality anime images, allowing it to generate detailed and aesthetically pleasing anime-style artwork. This includes characters, scenes, and environments with vibrant colors and clean lines.
- Text-to-Image Capabilities: The model takes textual prompts as input and generates corresponding anime-style images. Users can describe characters, scenes, and styles, which the model then translates into visuals.
- Customization and Control: While primarily focused on anime styles, Waifu Diffusion can be used for various creative purposes, including generating custom character designs and experimenting with different artistic styles.
- Community and Accessibility: The model is accessible through user-friendly interfaces like WebUI, making it easy for creators to generate and download anime-style images.

8. VQGAN+CLIP
AI art algorithms: VQGAN (Vector Quantized Generative Adversarial Networks), CLIP (Contrastive Language-Image Pre-Training)
License: MIT License
Repository: https://github.com/CompVis/taming-transformers; https://github.com/openai/CLIP
Online demo: None
Different from other text-to-image AI models, VQGAN and CLIP are two separate machine learning algorithms. They were combined and published on Google Colab by AI-generated art enthusiasts Ryan Murdock and Katherine Crowson. VQGAN creates images that resemble others, while CLIP determines how well a prompt matches an image. This led to a viral trend of people using the technique to create and share their own impressive artworks on social media platforms.
Unique Features of VQGAN+CLIP
- Hybrid Architecture: VQGAN generates images, while CLIP assesses how well these images match the input text prompts. This interaction allows for iterative refinement of the generated images to better align with the desired textual description.
- Text-to-Image Synthesis: VQGAN+CLIP can generate a wide variety of images from text prompts, ranging from realistic scenes to abstract and surreal compositions. It is particularly adept at capturing the essence of a textual description rather than just depicting literal elements.
- Customization and Control: Users can fine-tune the generation process by adjusting parameters such as the number of crops (cutn), step size, iterations, and initial images. This flexibility allows for experimentation with different styles and effects.
- Artistic Applications: VQGAN+CLIP is well-suited for artistic and creative applications, such as generating images for digital art, illustrations, or product designs. It can also emulate various styles, including those of famous artists or specific visual aesthetics.

9. Kandinsky AI
AI art models: Latent Diffusion U-Net
License: Apache License 2.0
Repository: https://github.com/ai-forever/Kandinsky-2
Online demo: https://replicate.com/ai-forever/kandinsky-2
Kandinsky is an open source AI artwork generator evolving for years. The recent v2.2 improves upon Kandinsky 2.1 with a new image encoder, CLIP-ViT-G, and ControlNet support, resulting in more accurate and visually appealing outputs and enabling text-guided image manipulation. Previously, models were trained on low-res images. Now it can create 1024x1024 pixel images and supports more aspect ratios.
Unique Features of Kandinsky AI
- Latent Diffusion Models: Kandinsky models, particularly Kandinsky 2 and later versions, utilize latent diffusion techniques. This approach involves creating images in a compressed latent space and then refining them to achieve detailed outputs.
- CLIP Integration: Kandinsky 2.1 incorporates the CLIP model for both text and image encoding, allowing for enhanced visual performance and the ability to blend images seamlessly.
- High-Resolution Images: Kandinsky 2.1 can generate high-resolution images up to 1024x1024 pixels, making it suitable for applications requiring detailed artwork.
- Multifunctional Capabilities: Later versions like Kandinsky 3 offer a range of functionalities including text-guided inpainting, outpainting, image fusion, and video generation.
- Cultural Nuance: Kandinsky models are trained on datasets that include a wide range of visual representations, particularly from Russian culture, which enhances their ability to capture nuanced cultural aesthetics.

How to Enhance AI-Generated Images
Existing open source AI image generators can create compelling images but are often constrained by resolution limits. The maximum of image resolution of most open source AI art creators is 1024px x 1024px or 2048px x 2048px. Moreover, running these AI models also demands powerful, expensive GPU hardware.
To address these limitations, you can use VideoProc Converter AI, an AI-powered image upscaling software that can enlarge and enhance images up to 10K resolution (10000px x 10000px). It leverages the state-of-the-art AI Super Resolution model to add realistic details and textures when enlarging low-res images, photos, and artworks from Midjourney, Stable Diffusion, DALL-E, etc.
Unlike running complex AI image models that put strain on your GPU and CPU, VideoProc Converter AI is optimized to efficiently upscale images with a user-friendly interface. It works even on moderate laptop and desktop hardware for hassle-free high-resolution AI image enhancement.

VideoProc Converter AI - Best Video and Image Upscaler
- Upscale images up to 10K and videos to 4K with clear and sharp details.
- The latest AI models for AIGC, low-res/pixelated footage, old DVDs.
- Enhance quality, denoise, deshake, restore images and videos in one go.
- Fast batch process. Smooth performance. No watermarks.
- Plus: edit, convert, compress, screen record, and download videos.
![]() Excellent
Excellent ![]()

Step 1. Launch VideoProc Converter AI. Hit "Image AI" and drag and drop images generated by AI to it.

Step 2. Choose an AI model. Real Smooth v3 is highly recommended for enhancing AI-generated images, anime, cartoons, and similar styles. If your image contains a lot of fine detail, Gen Detail v3 is also a great choice.
Step 3. Choose the scale, "2x", "3x", or "4x". You can right-click on the image file at the bottom to apply the upscaling settings to the rest. Or go on tweaking separately.
Step 4. Click the "RUN" to export.
FAQs about Open Source AI Image Generators
Are AI-generated images copyright free?
AI-generated artwork is not copyrighted or attributed to a person, but the existing artwork used to train the generator algorithms is often owned or attributed to real human artists and creators. Therefore, the ownership and attribution of the original artwork used to train the AI algorithm must be considered when using AI-generated images.
How to run an open source AI image generator on your computer?
There are multiple ways to run open source AI image generators. For instance, try online interactive demos, incorporate advanced AI capabilities into certain apps via APIs, run the source code with online programming tools like Google Colab, or get Python and Git installed to run a generative AI model file from GitHub or HuggingFace.
Can an open source license be revoked?
No, once an open source license has been applied to a particular version of software or code, it cannot be revoked for that version. However, for future versions, the license can be changed. This means that if you are using open source AI image generator models or algorithms for commercial purposes, it is important to check the latest license status to ensure that you are complying with the terms of the license.
Additional resources:
[1] Stable Diffusion Models: A Beginner's Guide
[2] Revolutionizing Open Source Licenses with AI Restricted MIT License
[3] Who owns AI art? - The Verge